NSDPY: Batch downloading from NCBI database with python3¶
![]()

![]()
Overview¶
nsdpy (NCBI sequence Downloader) aims to facilitate the download of large numbers of DNA sequences from the NCBI nucleotide database, sort them by taxonomic rank and if necessary, extract a specific gene from long sequences (e.g. mitochondrial genome) based on sequence annotations. Batch download for list of taxa is also possible. The main output is one or several fasta files (.fasta) and optionally Tab-separated value files (.tsv) with taxonomic information included in the description lines (see examples).
Major steps¶
Based on a user’s query the program queries the Entrez API from NCBI using the e-utilities tools (Entrez Programming Utilities, see this page for more information) to download the results available in the nucleotide database in fasta or fasta format containing only the coding DNA sequences (CDS) (see: Fasta files for the CDS). The user has the possibility to add one or more text files containing a list of taxa to be added to the query.
Optionally the program analyzes the results to extract the desired gene based on sequence annotation
The sequences are sorted to files according to the taxonomic precision required. To accomplish this sorting the program first downloads the taxonomic information for each sequence from the NCBI Taxonomy database. The user can choose to add the taxonomic information to the information lines of the sequences.
The output files are in fasta format (and optionally tsv) and contain the information as found in the raw file and optionally, the following information can be added:
organism name
protein ID (in the case of CDS)
TaxID
lineage
sequence length (for the tsv format)
Workflow¶
File Formats¶
For more information on the different file formats:
fasta file ( .fasta ): Wikipedia: fasta format
fasta for the cds ( .fasta ): a fasta file containing only the CDS. See: Select fasta cds from the GUI
GenBank ( .gb ): NCBI GenBank file
Tab-separated value file ( .tsv ): Wikipedia: Tab-separated value
Text file ( .txt ): File info
Motivations for the programming choices¶
Keep the use simple to allow users with a minimum of programming knowledge to be comfortable using the script.
Minimize the dependencies to minimize installation steps and maintenance issues.
Keep the script simple, available and open source to allow the users to modify it if needed.
Find a simple way to download the results from a request to NCBI database keeping track of the possible missing sequences.
Retrieve additional taxonomic information and automatically sort the results to save the user time-consuming manipulations.
To comply with these objectives two ways to use the program are available:
from the terminal: this allows the users to include the script in a pipeline and to run the script directly from their own computer. (see Instructions for use from the terminal)
from a google colab notebook (see: what is google colab?): this allows the user to run the program online (from any web browser) and download the results automatically in their google drive without having to install anything on their own machine (see: Instruction for use from Google colab notebook).
Instructions for use from the terminal¶
Requirements and installation¶
nsdpy is a command line application written in Python3 that can be run from a terminal in most operating systems (Linux, Windows, Mac). It is available on PyPI website and can be installed from the terminal.
Requirements¶
Python 3.8+: Python Downloads
pip3: pip installation
Install¶
As a package (simplest)¶
Note that for the following commands, depending on user environment pip3 may be replaced by pip
pip3 install nsdpy
To install the dependencies directly via pip3 (python3 package manager), download the requirements.txt file (available here) in your working directory then use the following command:
pip3 install -r requirements.txt
Download from GitHub¶
Alternatively, the script can be downloaded from GitHub NSDPY repository. The user only needs to download the nsdpy.py and functions.py files and have python 3.8+ (see: Python Downloads ) and the request library (see: requests documentation and request installation) installed (users may have to use the command pip3 instead of pip for python3 depending on their installation). This minimum installation should be enough to run the script. Otherwise, the requirements are listed in the requirements.txt file (see above).
To run nsdpy.py the user needs to have the files functions.py and nsdpy.py files in the same directory, then run it from this directory.
Minimum use¶
Once nsdpy is installed as a package the following commands can be run from the terminal. Open a terminal and enter a nsdpy command with a compulsory -r argument
nsdpy -r "This is a query to NCBI"
Example 1
The following command will download the fasta files for all results available in GenBank (see: What is GenBank? ) with COX1 in the title:
nsdpy -r "COX1[Title]"
or..
nsdpy --request "COX1[Title]"
These two requests are equivalent.
Let’s break this down:
nsdpy is the name program called by the terminal.
-r or –request just two different ways to call the same option, the first one being the shorthand notation of the second one.
“COX1[Title]” is the user’s query to NCBI in double quotes. It is the same format as the one you would use to query the nucleotide database on NCBI website.
Example 2
nsdpy -r "mitochondrion[Title] AND complete[Title] AND Bryozoa[Organism]"
This command will download the fasta files for all complete mitochondrial genomes of Bryozoa available in the nucleotide database.
Example 3
Download all sequences of four genera where COI is present in the title line:
nsdpy -r "(Parnassius[ORGN] OR Pieris[ORGN] OR Melithaea[ORGN] OR Iphiclides[ORGN]) AND COI[Title]"
This command is identical to the following:
nsdpy -r "COI[Title]" -L taxa.txt.
Where taxa.txt is a text file with each genus name in a separate line:
Parnassius Pieris Melithaea Iphiclides
GOOD TO KNOW . .
Help can be displayed by using the -h or –help option:
nsdpy -h
or..
nsdpy --help
Information on how to build a query to the NCBI search engine read the NCBI Help Manual.
Note that if the query has some white spaces or any other special characters it must be wrapped in quotes. On Windows terminal users must use the double quotes only.
Options¶
The options can be displayed by using the help as described above.
Version¶
-V (or –version) displays the nsdpy version and exits.
API Key¶
-a (or –apikey) provides an API key when calling the Entrez API. Users can get an API key by registering to the NCBI website ( Register here ). If no API key is provided the program works as well (it might be a little slower). To learn more about the API key see: New API Keys for the E-utilities .
Verbose¶
-v
or..
--verbose
Displays more text output in the terminal, such as progression of downloads and analysis.
-q
or..
--quiet
No text output is displayed in the terminal.
Note that the –verbose and –quiet options are mutually exclusive.
Gene selection¶
note that single quotes can be avoided if the pattern does not include any special characters such as ., +, *, ?, ^, $, (, ), [, ], {, }, |, or . .
-c 'PATTERN 1' 'PATTERN 2' ...
or..
--cds 'PATTERN 1' 'PATTERN 2' ...
The program will download the cds_fasta files instead of the fasta files. The cds_fasta file is a FASTA format of the nucleotide sequences corresponding to all CDS features. PATTERNS are optional. PATTERNS: regular expression for filtering genes from the cds_fasta files and GenBank files corresponding to the accession version identifiers resulting from the user’s query. The search is case insensitive. This option is particularly interesting when looking for a gene from organites whole genomes or from DNA sequences containing more than one gene.
Example for the COX1 (or COI) gene:
nsdpy -r "mitochondrion[Title] AND complete[Title]" -c 'COX[1I]' 'CO[I1]'
or..
nsdpy --request "mitochondrion[Title] AND complete[Title]" --cds 'cox[1i]' 'CO[I1]'
The above commands are identical.
Note that this option must be used separately from the others. For example to use the –cds option and the –verbose options these commands will run normally:
nsdpy -r "This is a query to NCBI" -c -v
nsdpy -r "This is a query to NCBI" -c 'pattern1' 'pattern2' -v
However, the following command will interpret the “v” as a pattern and not as the verbose option.
python3 nsdpy.py -r "This is a query to NCBI" -cv
output files¶
TaxIds¶
-T
or..
--taxids
The program will write a text file with the accession version identifiers found and their corresponding TaxIDs separated by a tabulation. Example:
nsdpy -r "ITS2" -T
Tab-separated values (–tsv or -t)¶
-t
or..
--tsv
The program will create two folders: “fasta” and “tsv”. The fasta folder will contain the results in fasta format and the tsv folder will contain the results in tsv format. Example:
nsdpy -r "Homo sapiens[Organism] AND COX1[Title]" -tsv
Information¶
Add the taxonomic information to the information lines of the sequences written in the output files.
-i
or..
--information
For the fasta files: add the Taxon name, protein ID (for the cds option only), TaxIDs and lineage to the information lines. In the output fasta files the taxon name is written without any spaces, eventual spaces are replaced by ‘_’. This is to help parsing these files automatically. For the tsv files the header line will appears to be: name (organism name), SeqID (accession version number and protein ID), TaxID, Lineage, sequence length, sequence.
Taxonomy¶
kingdom (–kingdom or -k)¶
-k
or
--kingdom
The program will write the results in different fasta files (one for the Metazoa, one for the Fungi, one for the Plantae and one for Others containing the sequence that doesn’t correspond to the above three kingdom) Example:
nsdpy -r "This is a query to NCBI" -k
phylum (–phylum or -p)¶
-p
or..
--phylum
The program will write the results in different fasta files, one file per phylum. Example:
nsdpy -r "This is a query to NCBI" -p
For the -k and -p options the phylums and kingdoms correspond to the following lists and can be modified by the user by adding or deleting entries directly in the functions.py script: Plantae = [‘Chlorophyta’, ‘Charophyta’, ‘Bryophyta’, ‘Marchantiophyta’, ‘Lycopodiophyta’, ‘Ophioglossophyta’, ‘Pteridophyta’,’Cycadophyta’, ‘Ginkgophyta’, ‘Gnetophyta’, ‘Pinophyta’, ‘Magnoliophyta’, ‘Equisetidae’, ‘Psilophyta’, ‘Bacillariophyta’,’Cyanidiophyta’, ‘Glaucophyta’, ‘Prasinophyceae’,’Rhodophyta’] Fungi = [‘Chytridiomycota’, ‘Zygomycota’, ‘Ascomycota’, ‘Basidiomycota’, ‘Glomeromycota’] Metazoa = [‘Acanthocephala’, ‘Acoelomorpha’, ‘Annelida’, ‘Arthropoda’, ‘Brachiopoda’, ‘Ectoprocta’, ‘Bryozoa’, ‘Chaetognatha’, ‘Chordata’, ‘Cnidaria’, ‘Ctenophora’, ‘Cycliophora’, ‘Echinodermata’, ‘Echiura’, ‘Entoprocta’, ‘Gastrotricha’, ‘Gnathostomulida’, ‘Hemichordata’, ‘Kinorhyncha’, ‘Loricifera’, ‘Micrognathozoa’, ‘Mollusca’, ‘Nematoda’, ‘Nematomorpha’, ‘Nemertea’, ‘Onychophora’,’Orthonectida’, ‘Phoronida’, ‘Placozoa’, ‘Plathelminthes’, ‘Porifera’, ‘Priapulida’, ‘Rhombozoa’, ‘Rotifera’, ‘Sipuncula’, ‘Tardigrada’, ‘Xenoturbella’]
levels (–levels or -l)¶
-l FILTERS
or..
--levels FILTERS
The program will write the results in different fasta files corresponding to the match between the FILTERS and the taxonomy. Example:
nsdpy -r "This is a query to NCBI" -l Deuterostomia Protostomia
The program will write one file for the Deuterostomia and one file for the Protostomia and one file for the others).
species (–species or -s)¶
-s
or..
--species
The program will write the results in different fasta files corresponding to the name of the organism. Example:
nsdpy -r "This is a query to NCBI" -s
The program will write one file for the each of the different lowest taxonomic level found.
nsdpy -r "This is a query to NCBI" -ssss
The program will write one file for the each of the 4th (notice the 4s) lowest taxonomic level found, if the lineage is,for example, cellular organisms, Eukaryota, Opisthokonta, Metazoa, Eumetazoa, Bilateria, Protostomia, Spiralia, Lophotrochozoa, Annelida, Polychaeta, Errantia, Phyllodocida, Nereididae, Platynereis the program will select Errantia).
More examples¶
Some options can be used together, for example a gene selection option can be used in combination with a taxonomy option and some file output options as well as a verbose option. Note that the order of the options does not matter.
Example 1:
nsdpy -r "mitochondrion[Title] AND complete[Title]" -c -iT
With these options the program will download the fasta files containing the CDS sequences (-c) for every result of the user’s query (-r), download and append the TaxIDs, organism name and lineage information to every sequence written in the output file (-i) and write a text file for the accession version identifiers and TaxIDs (-T)
GOOD TO KNOW . .
the -r option must be followed by the user’s query otherwise the program will return an error
options -T and -i can be written together as -Ti
-c option must be used separately.
Example 2:
nsdpy -r "mitochondrion[Title] AND complete[Title]" -c 'CO[1i]' 'COX[1i]' -vk
As in the first example, the program will download the fasta files containing the CDS sequences for every result of the user’s query (-r) but as some filters are provided after the -c option ( CO[1i] COX[1i]) the program will filter the results according to these regular expression.
About the filtering process:
The sequences are filtered according to the information line of their fasta file: if the regular expression used to filter the sequence is in the information line then the sequence is kept, otherwise it is not kept in the final result. If the sequence has no fasta file for the coding sequences the program downloads and parses the GenBank file ( .gb). In that file the program looks in the “product”, “gene” , “gene_synonym” and “note” fields to find the regex used as filter. It extracts the sequences according to these annotations.
The program will write information about the run and the number of sequences found in the terminal with the option -v. The sequences will be dispatched in different fasta files depending on their kingdom with the option -k.
-c 'CO[1i]' 'COX[1i]'
The program will filter the genes for which the annotation in the CDS fasta file or the GenBank file match the following regular expressions ( patterns): CO[1Ii] COX[1i].
Example 3:
nsdpy --request "CO1 OR COX1 OR COI OR COXI" -l Choradata Cnidaria
-l Chordata Cnidaria: the program will output three fasta files, one for the Choradata sequences, one for the Cnidaria sequences and one for the sequences that do not belong to the Chordata or the Cnidaria either.
Example 4:
nsdpy -r "(Parnassius[ORGN] OR Pieris[ORGN] OR Melithaea[ORGN] OR Iphiclides[ORGN] AND COI[Title] AND (2010[Publication Date] : 3000[Publication Date])
AND barcode[Keyword] AND mitochondrion[Filter]" -i -t
This command is used to download mitochondrial (mitochondrion[Filter]) sequences of four Lepidopteran genera (Parnassius[ORGN] OR Pieris[ORGN] OR Melithaea[ORGN] OR Iphiclides[ORGN]) published in NCBI nucleotide database since 2010 (“2010”[Publication Date]: “3000”[Publication Date]), with a barcode present in the keyword field (barcode[Keyword]). The request (-r) combines a series search term each of them limited to a particular field (e.g. Organism, Publication Date) of the GenBank record. Note the use of OR to link different names of the genera, to obtain sequences from all of them, and the use of parentheses to correctly structure the query. The -i option replaces the original definition lines to give taxonomically informative format more adapted for phylogenetic studies: taxon_name-SeqID | TaxID | Taxonomic lineage with coma-separated values. The -t option produces a tsv file with the following fields: Taxon name, SequenceID, TaxID, Taxonomic lineage, Sequence length, Sequence.
Note the exact same result can be obtained with following command:
nsdpy -r "COI[Ttile] AND (2010[Publication Date] : 3000[Publication Date]) AND barcode[Keyword] AND mitochondrion[Filter]" -i -t -L genus_list.txt
The genus_list.txt is a text file with the four Lepidopteran genera of interest (one genus name in each line). We used just a short list in this example, but it can contain thousands of taxaof any taxonomic level.
Output files¶
The script creates a folder named ‘NSDPY_results’ in the working directory and a subdirectory for each run named with the starting time of the run: /NSDPY_results/YYYY-MM-DD_HH-MM-SS/. In this last folder the script writes the fasta file(s) containing the results. If the –tsv option has been selected two folders called ‘tsv’ and ‘fasta’ are created to store the results in fasta and tsv format. If the –information option is selected, the information line of the output fasta files are as follows:
Organism name (eventual spaces are replaced by an underscore: _ )
Accession version identifier
_cds_ (if the –cds option is selected)
protein_id (if the –cds option is selected)
TaxID
Lineage
If the –information option is selected, the information in the tsv files are as follows:
Organism name
SeqID
TaxID
Lineage
sequence length
sequence
Different files are written depending on the selected taxonomy options and the tsv option. The following table summarize the different files and their attributes:

Example: The identification line of the output fasta file:
>Homo_sapiens-KY033221.1_cds_API65494.1_1 | 9606 | cellular organisms, Eukaryota, Opisthokonta, Metazoa, Eumetazoa, Bilateria, Deuterostomia, Chordata, Craniata, Vertebrata, Gnathostomata, Teleostomi, Euteleostomi, Sarcopterygii, Dipnotetrapodomorpha, Tetrapoda, Amniota, Mammalia, Theria, Eutheria, Boreoeutheria, Euarchontoglires, Primates, Haplorrhini, Simiiformes, Catarrhini, Hominoidea, Hominidae, Homininae, Homo
Homo_sapiens: Organism name
KY033221.1: Accession version number
API65494.1_1: protein ID
9606: TaxID
cellular organisms, Eukaryota, ….., Homininae, Homo: lineage
The first line of the tsv file:

Note that in this example the lineage and the dna sequence have been shortened to fit this document in the real tsv file the lineage and dna sequence are complete.
## Instruction for use from Google ColabUsing the notebook from Google colab doesn’t require any installation, it just needs a web browser. For an introduction about Google Colab see Welcome to Colaboratory.
The use of the notebook present the following advantages:
users don’t need to remain connected while the code is running as the script is run by the Google Colab servers
the execution of the script doesn’t use the user’s resources
the results can be accessed from any computer connected to Google Colab
Note that the maximum lifetime of the runtime is 12 hours after this time the script will stop running and the files saved in colab will be deleted, that can be an issue for downloading very big datasets. The files can be saved directly to the user’s google drive to avoid having to download them manually. To save space and downloading time the user can choose to retrieve the file as a .zip file. The notebook can be found here. To use it just open it and follow the steps described in the notebook.
Additional comments¶
Scripts¶
The nsdpy.py file contains the code to run from a terminal. It uses the functions located in the functions.py file.
Algorithm details¶
The script uses the Entrez programming utilities to access the NCBI databases ( see: A General Introduction to the E-utilities and for more: The E-utilities In-Depth: Parameters, Syntax and More).
The script takes a user’s query as input, the query is the same as the user would enter it in the NCBI search engine ( see: NCBI webpage for NCBI search engine and Entrez Searching Options on how to make a query). This query will be submitted to the esearch E-utility ( see: ESearch) in history mode by calling the esearchquery function from the functions.py file. The history mode will allow the program to get the ‘WebEnv’ and ‘querykey’ parameters. These parameters allow the program to later access the list of accession version identifiers corresponding to the results of the ESearch call and uses them to query esummary (see: ESummary) to retrieve the TaxIds. The program then uses esummary to search the taxonomy database calling the taxids function. The function finds the TaxIds corresponding to the accession version identifiers found by Esearch and optionally writes a text file with for each line the accession version identifiers and its corresponding TaxId separated by a tab and returns a dictionary (python doc on dictionaries, for a more basic approach: w3school tutorial) with the accession version identifiers as keys and TaxIDs as values. nsdpy.py lists the TaxIds returned by the taxids function to search the taxonomy database with Efetch and the default rettype and retmode parameters by calling thecompletetaxo* function if any of the Taxonomy options or the information is selected. This function will find the organism’s name (scientific name) and lineage of each TaxIds, then returns a dictionary with the TaxIds as keys and these information as values (yes.. a dict in a dict, it is called nested dictionaries). If the list option is selected nsdpy read the input text file and make a list of taxa. It takes one taxa per line. Then nsdpy takes the query entered in the request option (the only mandatory option) and add the taxa found in the provided text files as follow : BASE QUERY AND (taxon1[ORGN] OR taxon2[ORGN] OR taxon3[ORGN] ….) If the total length of the request is more than 2048 characters nsdpy will more than one query. If many queries have to be made nsdpy will creat a list of queries and iterates over this list to create a list of accession version numbers to be sent to the fasta or cdsfasta function. If the option cds is not selected main.py calls the fasta function to retrieve the fasta files and writes them in the output file(s). If the cds option is selected the Coding DNA Sequences (CDS) are downloaded in fasta format from the nuccore (see table1) database using Efetch by calling the cds_fasta function. The program makes calls to Efetch for 200 accession version identifiers at the time. For the cds option the results from Efetch are analyzed and filtered (optional) every time the program gets the result from a call. The analysis of the results from Efetch is made by the extract function (the call to this function is made directly by the cdsfasta function). The extract function looks for the genes specified by the user (the user can enter the gene as a regular expression. See this tutorial to learn about regular expressions and try your regular expression here), extract them and write them in a fasta file alongside. If the cds option is selected the program compares the accession version identifiers returned by the taxids function (which are the accession version identifiers found by ESearch) and the accession version identifiers for which a cds fasta file has been downloaded. It lists all the accession version identifiers for which no target gene has been found if a filter is provided or all the accession version identifiers for which no cds fasta file has been downloaded (if no filter provided) and sends this list to the taxo function. The taxo function performs a supplementary check for the accessions, where the gene is not found in the CDS fasta file. It searches the nuccore database with Efetch to get the GenBank files ( GenBank file format) for the accession version identifiers listed previously. It looks for the CDS sequences and eventually filters them and taxonomy information from this file. If no CDS is found for a given accession version identifiers, the accession version identifiers is appended to a text file named notfound.txt, otherwise the CDS is appended to the text file(s) written previously.
Supplementary material¶
About filtering¶
When the -c option is used with one or more filters the program will use the filter(s) provided by the user and interpret them as regular expressions.
First it will look for a match in the gene field of the fasta files it downloaded.
For example it the filter COX[1I] is used, the following sequence will be selected:

while the following won’t be selected:

This filtering can mostly be achieved without using the filter of the -c option by writing the correct request to NCBI. Then if the program doesn’t find a match for an accession version number in the cds-fasta file, it will download the GenBank file and look for a match in this file. The GenBank files have different fields that can be checked for a match ( see: GenBank file). The program will first look for a match in the “gene”, “gene_synonym”, “note” and “product” fields from the CDS file. If a match is found the DNA sequence will be extracted based on the CDS location information.
For example it the filter ‘CO[1I]’ is used, the following “note” field of the CDS section will be selected:
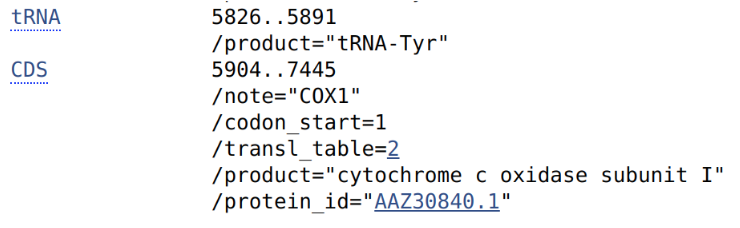

“note” field of the gene section can returns a match as well, in the following file the filter ‘COX[1I]’ was used:

“gene_synonym” field of the CDS section can be parsed as well to find a match. In the following sequence ( accession number: AB475096.1) the ‘CO[1I]’ was used:

Sometimes more than one match will be found, for example with the filter “COX[1I]”:

In the above example more than one result will be found for this reference. In the results.fasta file one sequence per match will be written. As well the accession number with more than one match will be displayed in the ‘duplicates.txt’ file with the number of matches it returned.
In some case the user can add more filter to match the product field, for example in the following case, no match is found with the COX[1I] filter, but if the user add the filter “cytochrome c subunit oxidase 1” the sequence would be selected because of the match in the ‘product’ field:

Fasta files for the CDS¶
The following figure displays how the fasta files containing only the cds are presented:

The following figure displays the how to select the fasta files containing the cds directly from NCBI user interface:

Comments¶
The scripts could be simplified and output almost the same results by using only the taxo function instead of using the cds_fasta function and then using the taxo function. This protocol has been tried but the running time (mostly due to the downloading time) was an order of magnitude longer. Minimizing the number of GenBank files analyzed is found to be a good way to minimize the running time as well as minimizing the possible errors in retrieving the CDS from DNA sequences as in the cds fasta files the CDS are already isolated while in the GenBank file the script has to find the location then extract the gene from the whole DNA sequence of the file.